
文章摘要moonshot-v1-8k
Standby API Responsing..
2026年,AI确实越来越聪明了。如果说早期的AI需要非常专业的prompt来辅助,现在已经发展到不太需要那么专业了,不论日常交流,学术研讨还是技术实现,从文字到音频,再从图片到视频,AI“猜”用户需求的能力毫无疑问已经越来越强了,AI能帮我们做的也越来越多。
最近做了两个事,一个是迁移valine评论,另一个是给wordpress的评论系统加了一些AI辅助。促使这次改版的是偶然看到了corrain 博文评论区中@AI自动回复,觉得和微信元宝很像,很方便,就想着改进一下wp评论。(其实凡哥那早就做了ai评论,当然,后续增强AI评论也是参考了该逻辑)
开发的时候我都没用最强coding claude,用的国产deepseek的专家模式,开启深度思考,现在实际体验真的很不错了。他的模型数据很大,我直接把问题抛给它,其中很多没提供的细节都是他自己拿到的。虽然不是什么一次成功,但效率提升不是一点半点。
@2BER AI
先说下这个 @2BER 评论增强AI,2BER被设计用来评论用户交流互动,一开始设计他的目的还是文章总结,不过后来发现当AI被设计到评论交互系统里后就变得特别灵活,可扩展性特别强。当你在文章下 @2BER (不带任何其他内容)时AI会自动返回当前文章摘要,在其他页面 @2BER 时,(若页面无内容)他会作为一名普通AI助手和你聊天(后续无需@)。后面我发现这样功能还有点单一,就再增强了他的属性,设计了多楼层评论、解析其他用户评论、多轮对话等复杂结构。
- 匿名对话(审核可见)
- 连续对话(数量限制)
- 楼层对话(引用评论)
- 失败重试(后台前端)
- 实时状态(即时响应)
因为 Valine 即将关闭服务,故此项在 wordpress 基础上开发。(对了,因为AI回复为即时前端输出 不具时效性,故AI回复的评论不会发送邮件通知,避免打扰到部分用户。若回复重试失败,可刷新页面后等待再重试,若请求超时且未发起重试请求或重试失败时,可等待博主在后台再次发起请求)

期间AI回复体验比之前好很多,很多你没考虑到的东西他会自己去设计并告知你具体用途,其实开启深度思考也有用,看看他的思路是什么,有时候他会抛弃掉部分实现思路,但是你能看见,就可以在他后续代码出错时尝试他之前的思路,有时候有奇效👍。
基础需求
// 需求:wordpress评论系统增加`@2BER`关键词触发AI自动回复用户评论内容,思路:通过`comment_post`钩子,截取检测评论内容若包含该关键词,则携带文章内容+用户需求发送到指定api请求给ai的api(如kimi),并等待api返回结果,将此结果(文本)作为该用户的子评论回复。
新增 REST API
// 对了,我想把这个功能设计成一个可调用的api接口,例如提供一个评论id,就可以去执行以上ai回复(如该评论已回复,则返回已回复内容)。请你保持上述代码不动的基础上修改
增强 API 响应
// 好的。现在我们来增强前端用户体验:目前执行ai回复时,前端不会有任何响应或提示,我的想法是可以先写入评论列表,显示等待响应(实际是否写入数据库,你来决定),等api响应后,再将实际返回结果写入前端评论。关于前端实现你不用管,把后端响应给我就行。
...
// ......AI 评论反垃圾
这个想法是我在 obaby 那偶然看到的,当时就觉得这个思路特别新颖,现在刚好给评论系统接入AI了,正好试试效果。其实这个反垃圾的效果和接入的模式应该有很大关系,后面怕误判又把被AI判定的评论搞到后台列表手动审核了,这个测试还有很大的改进空间。
AI 评论过滤
// 我最近发现被刷了很多垃圾评论,刚好我们评论钩子中加入了AI系统,所以我想加入AI评论审核。新需求:在原有基础上,新增一个AI内容审核函数,这个函数主要通过用户提交的评论内容进行审查过滤,垃圾评论的规则可以参考数据库中被标定为“垃圾评论”的评论数据,进行自我学习和判定。开这个AI助手用了几天时间,但实际开发成本很低,人工介入少,效果还好。现在,你可以在评论区尝试`@2BER`来获取你的专属AI回复啦!
所有功能及后台控件均已同步更新已到github beta-v1.4.4.*.
Valine 迁移
在Wordpress适配完2BER AI,想到现在还在用Valie的评论,虽然leancloud还有半年才关闭服务,想着干脆一次性迁移过去了事,反正之前都迁移实验过了,没啥问题。注意,执行任何操作之前,先备份数据再进行操作。
之前提到,leancloud将于27年初关停baas服务,届时valine依存的后端储存服务就没了,再早之前(23年)也提前做过迁移预演,只是时隔数年,再打开那篇文章的时候,很多东西自己都看不太懂了😂… 有不少bug和错误,记得那年还去研究了sql的好多语法来实现,搞得既复杂效率又底下。
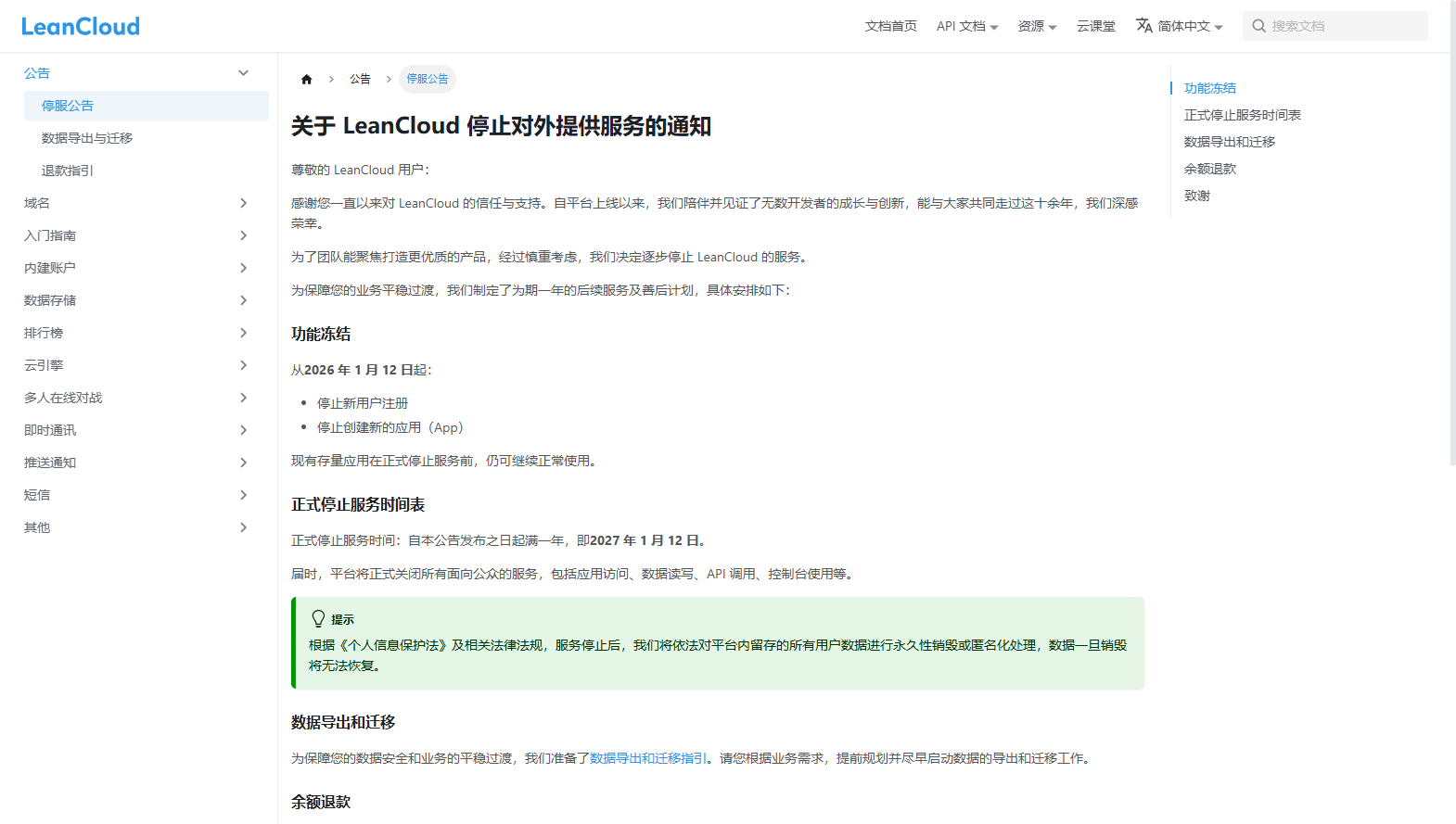
Leancloud 服务关停预告
关服公告 昨天查看 leancloud 后台数据的时候,一条公告映入眼帘:LeanCloud 将于 2027 年 1 月 12 日停止对外提供服务,详情...
不过好在,我们还有AI!
一开始只是尝试着问下,他刚开始搜了下网上的通用转换脚本,发现没有,就自定义写了匹配(这里他自己拿到了objectId, nick, mail, link, comment, insertedAt, url(文章路径),rid(父评论的objectId),ua等)。
基础需求
// 你有什么好办法把valine.js.org的评论jsonl数据,迁移到wordpress中吗?评论数据需要关联文章id(valine用的url),关联父级评论,以及关联评论数量。
Python+SQL 批处理
// 我在windows环境,”请确保已安装 mysql-connector-python(或 pymysql)“,我现在有comment.jsonl,也有mysql数据库信息,给我一个windows只需你的脚本的步骤AI给出的方案方便多了,本地Python脚本连接SQL远程数据库,全自动批量建立评论关联,插入wordpress数据库,一气呵成。虽然刚开始的方案不成熟,但几轮对话下来,很快便改进了实现方式。这里需要注意一点:如果他提供代码出问题了,要把全部报错信息和你的代码全部复制给AI。虽然AI支持长对话,但这样能最大程度减少隐形BUG出现。只要解题思路正确,AI能很快产出答案,但注意不用无脑复制粘贴,有时候AI会偷懒省略掉部分重复代码。还有,涉及到SQL数据部分,如果你开了 Memcached 缓存,记得清掉。
这里顺便贴一下Valine转Wordpress的Python脚本,复制粘贴为 migrate.py 文件后,再将leancloud导出的 jsonl 文件放再 migrate.py 文件相同目录下,执行 python migrate.py 等待即可。期间若出现“未匹配**”,去检查下url结构,wordpress后台有个固定链接,看下结构是不是一致 /wp-admin/options-permalink.php
另外使用这个脚本前需要提前告诉AI把脚本里的URL匹配模式改为你自己站点的URL结构。(PS:如果你没装python环境,可以先问下AI这段代码都需要装哪些运行环境,AI会根据你的具体需求改进代码。连接远程数据库需要开放数据库远程权限和放行3306端口,操作完成后记得关闭。)
展开 valine2wp Python 代码块(PID修复版)
#注意!这一版会插入数据前自动清空数据库,请备份和再执行
import json
import re
import mysql.connector
from datetime import datetime, timezone
from urllib.parse import urlparse, unquote, quote
# ========== 配置 ==========
JSONL_FILE = "Comment.0.jsonl" # 你的 JSONL 文件
DB_CONFIG = {
"host": "你的数据库地址",
"user": "数据库用户名",
"password": "数据库密码",
"database": "数据库名",
"charset": "utf8mb4"
}
TABLE_PREFIX = "wp_"
# ==========================
conn = mysql.connector.connect(**DB_CONFIG)
cursor = conn.cursor()
# 1. 清空并确保字段
cursor.execute(f"TRUNCATE TABLE {TABLE_PREFIX}comments")
cursor.execute(f"ALTER TABLE {TABLE_PREFIX}comments MODIFY comment_content LONGTEXT")
# 2. 获取文章 slug 映射
cursor.execute(
f"SELECT ID, post_name FROM {TABLE_PREFIX}posts "
f"WHERE post_type IN ('post','page') AND post_status='publish'"
)
rows = cursor.fetchall()
print(f"查询到 {len(rows)} 篇文章")
slug_to_id = {row[1].lower(): row[0] for row in rows}
def get_candidate_slugs(url_str):
path = urlparse(url_str).path.strip("/")
if not path: return []
raw = path.split("/")[-1]
try:
decoded = unquote(raw)
encoded = quote(decoded, safe='').lower()
except:
encoded = raw.lower()
candidates = [encoded]
m = re.match(r"^\d{2}-\d{2}-\d{4}_(.+)", encoded)
if m:
candidates.append(m.group(1))
return candidates
# 3. 读取并解析所有评论,按时间升序排序
all_comments = []
skipped = []
with open(JSONL_FILE, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line: continue
c = json.loads(line)
candidates = get_candidate_slugs(c.get("url", ""))
post_id = None
for slug in candidates:
post_id = slug_to_id.get(slug)
if post_id: break
if not post_id:
skipped.append((c.get("url", ""), candidates))
continue
# 时间解析
try:
ts = c.get("createdAt", "").replace("Z", "+00:00")
dt = datetime.fromisoformat(ts)
gmt = dt.strftime('%Y-%m-%d %H:%M:%S')
local = dt.astimezone().strftime('%Y-%m-%d %H:%M:%S')
except:
now = datetime.now()
gmt = now.strftime('%Y-%m-%d %H:%M:%S')
local = gmt
user_id = 1 if c.get("mail", "").lower() == "xty@2broear.com" else 0
all_comments.append({
"post_id": post_id,
"author": c.get("nick", "")[:200],
"email": c.get("mail", "")[:100],
"url": c.get("link", "")[:200],
"content": c.get("comment", "")[:200000],
"date": local,
"date_gmt": gmt,
"approved": '1',
"agent": c.get("ua", "")[:255],
"oid": c.get("objectId"),
"pid": c.get("pid", ""), # ⚠️ 只用 pid
"user_id": user_id,
"created_dt": dt # 用于排序
})
# 按时间升序排列(确保父评论必在子评论前)
all_comments.sort(key=lambda x: x["created_dt"])
# 4. 插入
oid_to_new_id = {}
insert_sql = (
f"INSERT INTO {TABLE_PREFIX}comments "
"(comment_post_ID, comment_author, comment_author_email, comment_author_url, "
"comment_content, comment_date, comment_date_gmt, comment_approved, comment_agent, "
"comment_parent, user_id) "
"VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
)
for c in all_comments:
parent_id = 0
pid = c["pid"]
if pid: # 有直接父评论
parent_id = oid_to_new_id.get(pid, 0) # 此时父评论一定已插入
# 如果 pid 不在映射中(理论上不会),就降为顶级
data = (
c["post_id"], c["author"], c["email"], c["url"],
c["content"], c["date"], c["date_gmt"], c["approved"],
c["agent"], parent_id, c["user_id"]
)
cursor.execute(insert_sql, data)
new_id = cursor.lastrowid
oid_to_new_id[c["oid"]] = new_id
# 5. 更新评论数
cursor.execute(
f"UPDATE {TABLE_PREFIX}posts p "
f"SET comment_count = (SELECT COUNT(*) FROM {TABLE_PREFIX}comments c "
f"WHERE c.comment_post_ID = p.ID AND c.comment_approved = '1') "
f"WHERE p.post_type IN ('post','page')"
)
conn.commit()
cursor.close()
conn.close()
print(f"导入 {len(all_comments)} 条评论完成!")
if skipped:
print(f"\n未匹配的评论数: {len(skipped)} 条")
print("详细信息:")
for url, cands in skipped:
print(f" URL: {url}")
print(f" 尝试过的 slug: {cands}")
print()艹!又被AI耍了一道!!
迁移几天才发现,一大堆数据结构居然没关联上😅!(关键是这个坑几年前旧踩过了,没想到AI也tm没反应过来),就是父评论和子评论关联id,deepseek给的代码默认关联的是rid,但数据结构是这样的:任何评论下的子评论都有rid.. 这尼玛子评论关系不乱了吗?最无语的是我几年前那篇文章里还着重提了用pid代替rid来对应objectid..
好家伙,这ai也是一直没发现,迁移完就没注意这些,再加上新评论是正常的结构关系,要不看之前的结构压根发现不了… 昨晚紧急修复,ai也是发现了问题所在,经过多次微调,现在所有数据恢复正常。所以说啊,不能全信ai,ai也是从网上找的信息,没法确定真实性,有数据处理需求还是要把样本发给ai评估分析了再处理。
加上这几天又加了ai评论,还好数据量还没那么大,单独导出这阵子新增的数据后,让ai优化了导入逻辑,导入评论后在phpmyadmin执行评论数量更新sql,刷新memcached缓存,终于.. 又发现了新bug!导入后的有些评论id莫名很小,这说明ai的py脚本没有进行排序插入,头大!又让ai改了一版,一切正常。
评论数量SQL更新语句
UPDATE wp_posts p
SET comment_count = (
SELECT COUNT(*) FROM wp_comments c
WHERE c.comment_post_ID = p.ID AND c.comment_approved = '1'
)
WHERE p.post_type IN ('post','page');小结
AI辅助开发的故事告一段落,短短时间就完成了两个任务标的。不得不说,这玩意有时候是真好用!
评论留言











 ,之前还是在凡哥那边看到的类似idea,博主这个类似微信公众号元宝的功能
,之前还是在凡哥那边看到的类似idea,博主这个类似微信公众号元宝的功能 






