
文章摘要moonshot-v1-8k
Standby API Responsing..
前言
老早就计划着这件事了,知道长期使用第三方提供的数据服务可能那天就会挂掉的几率(比如之前的leancloud限制云引擎及域名回收事件),放在第三方或多或少会影响到部分使用其免费服务的群体,但毕竟人家是免费提供到的服务,我们白嫖的就不要在这里说三道四了,只是就事论事来讲数据还是存放在自己的手中最安全可靠。
数据迁移
一直以来leancloud都提供了数据导出服务,格式为 json line(jsonl),这里其实很方便了,因为市面上大多数评论系统都可以json格式的数据进行导入迁移数据,也就是说我们只需要把导出的 jsonl 格式转为 json 即可兼容大部分评论系统。此前为有考虑过 twikoo 评论,因其部署在 vercel 也比较放心,但无奈导入评论时报错没找到原因,故搁置。
此前开源主题时已经做了 wordpress 评论兼容,只是没有把魔改valine上的ui及功能移植过去,现在也就打算将存放于 leancloud 的 valine 评论数据导入到 wordpress 数据库内,一个为了做备份(几千条数据万一丢了就不好了,虽然经常有在导出备份),另一个就是想后期把 wordpress 评论给改一下,以后如果 leancloud 不再提供服务时就用 wp 评论平替,算是一个备选方案。
这里在做个备份及导入规则等操作记录,方便以后查阅。
数据更新(前提)
在导入 mysql 前,如果有些 valine 生成(或者我们自定义的)的数据项我们不想要(如 ACL/isNotified 等等),这时候我们需要将 jsonl 格式转为 json 格式( convertjson.com可在线转换)。
使用本地编辑器打开 .jsonl 文件删掉第一行的 filetype:JSON-streaming {"type":"Class","class":"Comment"} 后 ctrl+f 查找 }+换行符(ctrl+enter 或 \n)替换为 },+换行符,最后使用 [] 将所有对象包裹即可。
利用正则表达式将评论数据中那些不需要的数据一一项剔除掉,下方存档参考用。注意:必须将 ACL 及 insertedAt 两个数据删掉,否则可能影响后续数据转换操作!tips:貌似 leancloud 导出数据时无法自定义列及删除上述两列
,"ACL".*?,"objectId" 替换 ,"ACL".*?,"objectId" //访问控制对象
","insertedAt".*?\}," 替换 "," //插入时间对象
"updatedAt".*?," //更新时间对象
"," //替换
,"isNotified":.*?\} 替换 } //已发件提醒
//自定义对象
,"md5mail".*?,"
,"mailMd5".*?,"
,"ip".*?,"
,"ads".*?,"
," //以上替换
,"topset":.*?\},
}, //替换
"isEdited".*?,"
" //替换
<a class=\\"at\\".*?/a> , // 替换评论中所有 @人员 信息为空(wp函数加载评论时自动添加@人员)数据转换(参考)
可无视在线数据转换操作,所有 json to sql 均可在 phpmyadmin 及参考下方数据关联的 navicat 软件中进行数据转换操作
众所周知 wordpress 使用的是 mysql 数据库,那么json是不能直接用的,所以需要再到上述网站将 json 转换为 sql 格式,最后在 phpmyadmin 中导入 sql 数据到 wordpress 数据库。注意:此处数据转换需上外网访问,否则第二步(Step 2: Choose output options)时无法加载出数据导出选项!
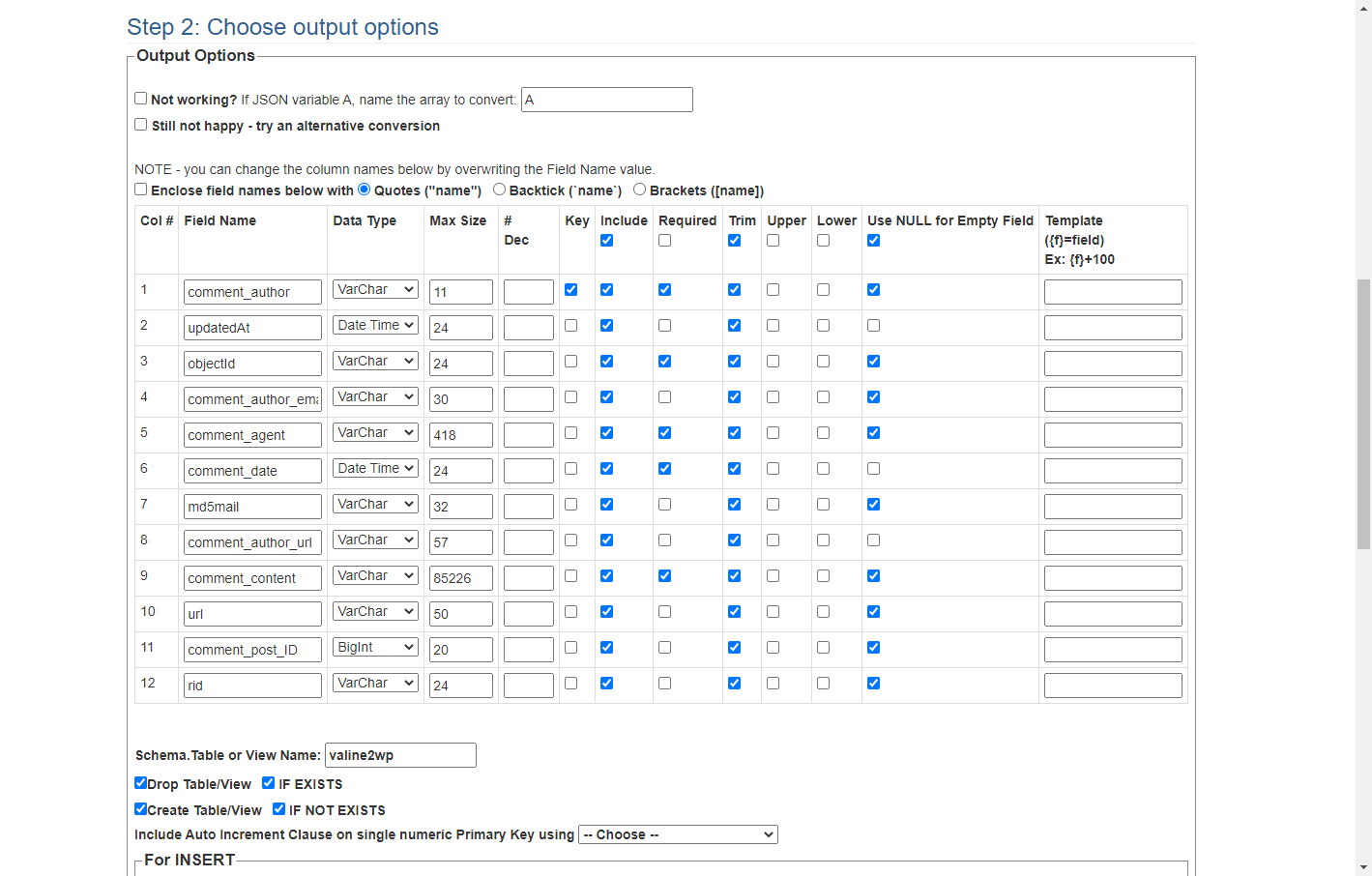
完成 json 到 sql 到转换后,将转换后的 sql 文件下载到本地,根据 wp 数据库中自带的 wp_comments 数据表结构进行进一步编辑,以下是我的编辑参考(务必提前将 wp_comments 数据表结构更改为上面转换好的结构)可以先拟个表(valine2wp)导入测试正常上传后,再做其他操作。注意:此处需手动新增设置 comment_ID 字段为递增及主键,否则可能影响后续操作。
DROP TABLE IF EXISTS valine2wp;
CREATE TABLE IF NOT EXISTS valine2wp(
comment_ID BIGINT(20) NOT NULL AUTO_INCREMENT PRIMARY KEY
,comment_author VARCHAR(11) NOT NULL
,updatedAt DATETIME NOT NULL DEFAULT '0000-00-00 00:00:00'
,objectId VARCHAR(24) NOT NULL
,comment_author_email VARCHAR(30)
,comment_agent VARCHAR(418) NOT NULL
,comment_date DATETIME NOT NULL DEFAULT '0000-00-00 00:00:00'
,md5mail VARCHAR(32)
,comment_author_url VARCHAR(57)
,comment_content VARCHAR(85226) NOT NULL
,url VARCHAR(50)
,comment_post_ID BIGINT(20) DEFAULT 0
,rid VARCHAR(24)
,comment_karma INT(11) NOT NULL DEFAULT 0
,comment_approved VARCHAR(20) NOT NULL DEFAULT 1
,comment_type VARCHAR(20) NOT NULL DEFAULT 'comment'
,comment_parent BIGINT(20) NOT NULL DEFAULT 0
,user_id BIGINT(20) NOT NULL DEFAULT 0
);
当一切正常导入并正常运行后,此时我们需要进行下一步操作评论数据之间的关系(在 Step 3: Generate output 时如果是测试表可以选第一个 JSON To SQL Insert,如果是更新 wp_comments 表可以选第二个 JSON To SQL Update。需要注意的是如果存在原生 wp_comments 表内没有的字段,则需在 wp_comments 表内新建或在 Step 3 生成 sql 时前取消勾选该字段 Include 选项)。
数据关联(主要)
在关联数据时,我们需要解决以下2个问题:
- valine/wordpress 是如何关联评论数据到对应页面的?
- valine/wordpress 是如何关联子评论数据到父评论的?
首先,在 valine 中通过查看源码或 leancloud 数据结构可以看到评论数据是通过页面 url 来进行关联的,而 wordpress 在其评论数据表中是通过 comment_post_ID 字段来分别对应到各文章 id 的。其次,valine 是通过每条评论中的 objectid 及 rid(reply objectId 主楼)comment_parent(默认 0)字段来关联其对应其评论的 comment_ID 字段。
了解完双方评论的基本原理后,就可以上手操作关联数据了。
关联文章页面
首先我们需要利用 valine 中提供的 url 字段来分别匹配 wordpress 数据库中对应的文章 slug 别名的文章id(也就是把 url 转换为其文章对应的 comment_post_ID),这里我是写了个简单的 php 文件来读取 json 文件并遍历获取每个对象的对应文章 id 后再写入 json 进行新增的(很傻,而且速度不快),其实这里可以直接在 phpmyadmin 中使用 mysql 语句进行批量替换的,就不用这么麻烦了!虽然是个笨办法,不过也还能用,简单做个记录(在wp根目录创建以下php文件,再将之前转换后的 json 数据丢到根目录访问即可。一点需要注意的是需要修改 $url 变量规则为你自己的 url 别名匹配规则)。
<?php
define('WP_USE_THEMES', false); // No need for the template engine
require_once( 'wp-load.php' ); // Load WordPress Core
// 通过文章别名模糊匹配文章id
function get_post_like_slug($post_slug) {
global $wpdb;
$post_slug = '%' . $post_slug . '%';
$pid = $wpdb->get_var($wpdb->prepare("SELECT ID FROM $wpdb->posts WHERE post_name LIKE %s", $post_slug));
return get_post($pid);
};
global $wpdb; //使用 wpdb 查询所有文章id
$wp2valine = $wpdb->get_results("SELECT url FROM wp2valine WHERE 1 ORDER BY comment_ID ASC");
//读取同目录 json 文件
$filename = "jsonl2json.json";
$handle = fopen($filename, "r"); //读取二进制文件时,需要将第二个参数设置成'rb'
$contents = fread($handle, filesize ($filename)); //通过filesize获得文件大小,将整个文件一下子读到一个字符串中
fclose($handle);
// 写入文章 id 到每个 json 对象
$decode = json_decode($contents); //解码 json
foreach ($wp2valine as $index => $res){
$urs = $res->url;
$url = substr($urs, strpos($urs, '_')+1, strlen($urs)); //注意⚠️修改此规则为你文章 url 别名规则
$uid = get_post_like_slug($url)->ID;
array_push($comment_post_ID, $uid);
$decode[$index]->comment_post_ID = $uid;
};
// 输出新的 json 文件
ob_start();
print_r(json_encode($decode,JSON_UNESCAPED_UNICODE)); //使用 JSON_UNESCAPED_UNICODE 参数来正确输出 emoji 表情
$content = ob_get_contents();
ob_end_clean();
file_put_contents(ABSPATH . '/output.json', $content);
?>完成上述操作后,应该能在wp根目录看到生成的 output.json 文件,打开会发现每条 json 对象已经新增对应的 comment_post_ID 文章id对象;再之后将 output.json 在 convertjson.com/json-to-sql 转换为 sql 数据库文件后重新导入到 wordpress 数据库查看运行测试。
⚠️注意!确保非 null 字段不存在 null 值!
关联父级评论(注意项)
完成评论数据文章关联后就剩最后一步了,关联子评论到父级评论,利用上面提到的原理操作即可,这次我选择直接使用 mysql 进行数据库更新,这样就告别了繁琐的读写删改 json 及转换步骤了。下面是实现评论关联的 mysql 条件语句及示意图(部分选中数据仅作观察对比)。
原理很简单,
通过对比评论数据表中的
objectid与pid字段,如果相同则表示其为父子关系(提取符合的所有数据行),然后提取父级(objectid)的comment_ID字段将其写入到pid数据行(子评论)中的comment_parent字段即可。
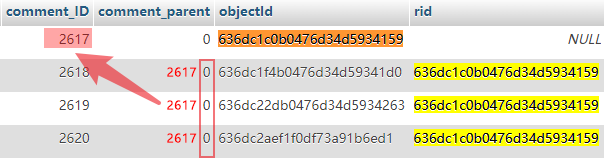
⚠️注意⚠️:不可直接上传已转换 json 的 sql 文件到服务器上的
wp_comments数据表执行comment_parent数据关联,这样会导致 wordpress 评论数据表发生改变!会影响comment_parent字段写入成功后续 wordpress 无法正常读取!我们需要在本地完成所有comment_parent字段的 sql 数据关联操作,可参考以下方案。
操作环境: windows mysql + navicat for mysql(留意当前需处理的 sql 文件数据结构必须与 wordpress 数据库中导出 wp_comments 数据表保持一致!)建议提前在原数据库内重新设计表,新增 objectId、pid、uid 等字段再导出,参考 sql 语句
ALTER TABLE `wp_comments` ADD `objectId` VARCHAR ( 24 ) CHARACTER
SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL AFTER `user_id`,
ADD `pid` VARCHAR ( 24 ) CHARACTER
SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL AFTER `objectId`,
ADD `rid` VARCHAR ( 24 ) CHARACTER
SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL AFTER `pid`,
ADD `url` VARCHAR ( 255 ) CHARACTER
SET utf8mb4 COLLATE utf8mb4_unicode_520_ci NOT NULL AFTER `rid`;<?php
//... UTC时间格式化参考
foreach ($decode as $index => $res){
$utc_date = $decode[$index]->comment_date;
$utc2date = date('Y-m-d H:i:s',strtotime($utc_date));
$decode[$index]->comment_date = $utc2date ? $utc2date : '0000-00-00 00:00:00';
}
//...
?>- 首先将 wordpress 数据库中的
wp_comments数据表新增字段后导出 sql 文件。 - 然后在 navicat mysql 编辑器中右键运行 sql 文件导入
wp_comments.sql文件(需要将原有数据删除,在设计表选项卡中将自动递增设置为1),之后将已关联commetn_post_ID字段的 json 文件导入到刚加载的 sql 文件中(⚠️注意 json 中的comment_date日期字段如果是 utc 格式需要使用 php 函数 date(‘Y-m-d H:i:s’,strtotime($utc_date)) 转换为普通日期格式 Y-m-d H:i:s 后再导入到 sql 文件,参考上方UTC时间格式化)(⚠️注意:若导入时候数据映射步骤显示不全,则表示 json 对象中的首行中未包含缺失的数据 key,导入数据首行必须包含所有所需字段(包括””空值),否则导入后将缺失该字段 value 值) - 执行下方 sql 语句通过对比
pid与objectId值将comment_parent_IDcomment_ID。(2k+数据执行时长大概在 5s) - 导入完成后将处理好的数据表右键转储为 sql 文件(包含数据和结构)导出为 sql 后再导入到 wordpress 数据库即可覆盖 wp_comments 数据表即可。
# 注意执行 SELECT ... FOR UPDATE 时无法模拟执行,请提前备份好数据再操作!
SELECT
objectId.comment_parent,
objectId.pid,
pid.comment_ID,
pid.objectId
FROM
`wp_comments` objectId,
`wp_comments` pid
WHERE
objectId.pid = pid.objectId FOR UPDATE; #保留分号否则报错
UPDATE `wp_comments` objectId,
`wp_comments` pid
SET objectId.comment_parent = pid.comment_ID
WHERE
objectId.pid = pid.objectId
#可选执行(更新评论GMT时间)
UPDATE `wp_comments` SET comment_date_gmt = DATE_SUB(comment_date,INTERVAL 8 HOUR) WHERE 1 #计算GMT时差(DATE_SUB()和DATE_ADD()函数)一开始我查了很久,因为不知道单表多字段查询如何通过 update 直接修改,所以选择使用 select for update 进行修改,测试可用,速度也很快。需要注意的就是 for update 后 update 的时候也需要带上 WHERE 条件(同 select 条件),否则修改后 comment_parent 全部变成 1..
关联评论数量
完成上述操作后导入 wordpress 的 mysql 数据库应该就能在对应文章/页面中加载出对应评论了,下面是统计文章评论数量,需要先把 wp_posts 表导出至本地(注意备份)。在 valine 中可直接通过 xhr 请求的 json 对象返回长度判断评论数量,而 wordpress 中则是储存在 wp_posts 数据表中的 publish(已发布) 页面/文章下的 comment_count 字段中,这里我们通过交叉查询(cross join)来实现 mysql 中两表数据的查询及更新操作
使用
GROUP BY将查询到符合 wp_posts/wp_comments 中符合条件的COUNT(*)数量CROSS JOIN交叉合集为res表,然后对比 res 表 ID 及 wp_posts 表 ID,最后将 res 表中的 count 写入 wp_posts 中的comment_count
UPDATE `wp_posts` t1,
`wp_comments` t2
CROSS JOIN (
SELECT
ID,
COUNT(*) AS cnt
FROM
`wp_posts` t1,
`wp_comments` t2
WHERE
t1.post_status = "publish"
AND t2.comment_post_ID = t1.ID
GROUP BY
t2.comment_post_ID
) AS res
SET t1.comment_count = res.cnt
WHERE
t1.ID = res.ID
AND t1.post_status = "publish";
#!在 WHERE 条件中需要对比目标 table id 及查询结果 table id,否则执行更新后都是同一个数值
#需要在交叉查询时返回查询结果 id 用作 update 更新时的条件小结
这次数据迁移持续了几天,总的来说还是比较满意,至少成功把数据对接好了嘛~还了解了几个 mysql 语法顺便也拓展了下 php 处理 json 数据之间的方案。
1122更新,近几天来来回回修订了好几个版本,现在算是确定了。一开始的 phpmyadmin 转 sql to json 再处理 json 转 sql 再到在线网站设计 sql 数据表后导入 wordpress,到现在直接使用 navicat 编辑、设计、导入转出全程本地化处理(总感觉太依赖线上服务不太好,万一以后要再做迁移不能用就麻烦了),处理数据的逻辑更清晰了,顺便只保留了几个与 valine 关联的字段方便以后使用。一个建议的话就是导入数据能在本地处理的就不要到线上使用 sql 处理,否则可能引发一系列不可预料的问题。毕竟数据提供好了,才方便数据库处理。
1129更新,处理完评论数量数据关联总算是告一段落了..





